기본 개념
Data type
내가 사용할 수 있는 값의 집합 + 내가 행할 수 있는 연산의 집합
integer 변수와 boolean 변수에는 같은 값이 들어갈 수도 있다. (Variable은 최소 할당가능한 크기가 ‘바이트’이기 때문)
boolean은 한 바이트에 0 또는 1의 값이 들어가도록 제한. 그리고 integer와 boolean이 행할 수 있는 연산은 다르다.
Descriptor
Variable의 타입마다 하나씩 따라다닌다.
Variable을 꾸미는 값
int a에 대해서, a의 속성을 갖고 있다. Variable을 관리할 때, 시스템이 필요한 정보를 모아 놓는다.
scope이나 lifetime은 굳이 변수 하나마다 따라다니면서 저장할 속성은 아니다. 코드 자체적으로 정해지기 때문
value를 집어넣을 필요는 X, 실제 메모리에 들어있는 것이기 때문
Object
user defined type이 메모리에 올라가서 instance가 된 것
모든 variable이 메모리에 올라가 있는 것
숫자에 관해서 C/C++에는 있는데 Java, Python에는 없는 것? => unsigned
-> 예전에는 메모리가 부족하던 시절, 한 비트라도 아끼기 위해서 생김 (Java랑 Python도 쓰는 방법이 있긴 함)
C에 있는 void는 Python에는 없다. (소프트웨어의 Reliability에 문제가 생김으로 사용을 자제하는 것이 좋다.)
C 언어 자료형
- Primitive(기본형)
- Non-primitive(파생형)

JAVA의 자료형
- 참조 자료형에는 모든 객체가 다 들어간다.
- 객체가 메모리에 올라가면 instance가 되고 그 instance를 가르키는 것이 참조 자료형
Python
Dynamic Type Binding을 하기 때문에 타입을 선언할 필요가 없다.
지원되는 자료형은 Java와 비슷.
포인터와 배열이 없다.
그러나 리스트가 자료형으로 있다.
튜플, Hash 구조, Dictionary 구조도 있다.
Reliability 떨어질 가능성 있음
Primitive Data Types
소프트웨어의 처리 없이 하드웨어에서 그대로 가져왔을 때, 의미를 가질 수 있는 타입. 보통 숫자 or 문자
- Integer(정수형) : 최대 8가지가 있다. short int long byte + unsigned 4개 / 수학적 연산 가능
- Floating Point : 소수점이 움직이면 Floating Point, 안움직이면 Fixed Point. =>
Fixed Point는 Decimal형으로 선언. 보통 128비트 중 64는 Exp, 64는 Fraction
(C/C++은 지원이 안된다.) - Complex(복소수) : Python만 지원(데이터 타입). C/C++은 헤더를 선언 후 사용, Java는 클래스로 만들어서 사용
- Decimal : 돈을 관리하는 프로그램에서 사용(COBOL 등), C#, Java, Python도 지원. C/C++은 지원 안함. BCD(Binary-Coded Decimal)형태로 고정된 소수점 자리를 저장 / 장점 : 정확성 / 단점 : 범위가 제한적, 메모리 낭비
BCD란? 십진수의 각 자리수를 4비트 2진수로 변환해서 표현 / 10진수 123은 0001 0010 0011로
Gray Code란? 3비트 Gray 코드에서 1은 001, 2는 011, 3은 010, 4는 110, 5는 111, 6은 101, 7은 100의 이진 코드로 표현
인접한 숫자를 사용하는 경우가 많아서 인접한 두 수 사이에서 딱 한 비트만 변하는 이진 코드인 Gray 코드가 더 좋다. - Boolean : True 또는 False, 주로 논리 연산. 한 비트로 표현하는게 맞지만 메모리셀 특성상 바이트로 표현 / 장점 : Readability
- Character : 숫자로 저장 / 숫자가 들어가서 코드 변환표에 의해서 문자로 바뀐다. (ASCII-127개의 문자(7개 비트)) 한글 등은 안되기 때문에 Unicode가 만들어졌다. 캐릭터 하나당 두 바이트가 필요하다. (UCS-2타입) (UCS-4는 4바이트를 씀)
- Chracter String Types (문자열) : Writability를 높여준다.
- Enumeration Types (열거형 자료형)
Named Constants이다. 즉 문자로 이름 붙인 상수 값. 범위는 내가 나열한 값들의 범위
Readability가 좋다. Reliability도 좋다. (정의된 범위 밖에서는 값을 가지지 않으므로 문제가 생긴다. 에러를 빨리 발견) - Array Types
같은 타입의 여러 변수들을 하나로 모은다. 첫 번째 요소에 대해 상대적 위치에 따라 식별. 인덱싱(서브스크립팅)은 인덱스에서 요소로의 매핑이다. 인덱스 문법은 [ ]을 이용한다. 예전 컴파일러에서 C/C++은 Array Index Checking을 안했다. (a[100]짜리인데 a[200]에 값이 들어감) - 할당되는 메모리 영역에 따라서 Array의 종류를 4개로 나눈다.
일부 언어에서는 저장 공간 할당 시 초기화를 허용
- C, C++, Java, C# example : int list [ ] = {4, 5, 7, 83}
- Character strings in C and C++ : char name [ ] = ″Michael″;
- Arrays of strings in C and C++ : char *names [ ] = {″Bob″, ″Jake″, ″Joe″};
- Java initialization of String objects : String [ ] names = {″Bob″, ″Jake″, ″Joe″};
자바의 배열은 배열 변수를 선언했다고 배열이 자동으로 만들어지지 않음. 배열 변수는 단지 참조 변수
자바 배열은 배열 크기가 실행 시간에 결정되는 일종의 객체
Heterogeneous Arrays : 다른 타입의 요소를 가지는 배열 (Python, JavaScript 등)
APL은 배열 연산에 대한 많은 연산을 제공하는 언어. (4개 중에는 Python이 가장 많이 제공)
rectangular 배열은 모든 행이 동일한 요소 수를 가지고 있고 모든 열이 동일한 요소 수를 가진 다차원 배열 jagged 배열은 요소 수가 다른 행을 가진 다차원 배열. 다차원 배열이 배열의 배열로 나타날 때 가능. jagged arrays는 같은 열(차원)에서만 같이 주소를 놓고 행끼리는 다른 공간에 존재할 수 있다.
Slice는 배열의 서브 구조이다. 참조하는 매커니즘. C/C++은 배열 슬라이싱을 지원 안 한다. (요소 순회만 가능)
mat = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] 에서 mat [0] [0:2]는 mat의 첫 번째 행의 첫 번째 요소와 두 번째 요소
배열은 시작 위치만 주어지면 뒤에는 연속된다. descriptor에는 시작 주소만 있으면 된다.
(descriptor는 컴파일러나 인터프리터가 우리가 짠 코드를 보고 변수 각각에 붙여주는 자료 구조)
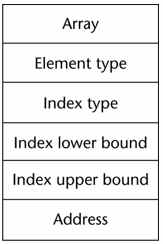
Data type : Array인 것을 알림
배열의 요소가 무엇인지 설명 (size도 같이 알 수 있다)
인덱스 타입 : 거의 대부분 숫자
낮은 인덱스
높은 인덱스
시작 부분의 주소
Associative Arrays
키를 통해서 값의 요소를 찾아가는 배열. 키와 값이 1:1로 매핑. (해쉬 구조, 딕셔너리)
Perl의 예시 : %hi_temps=("Mon"=>77,"Tue"=>79,"Wed"=> 65,…);
$hi_temps{"Wed"}=83; 하나를 읽어내면 스칼라 값으로 바뀌므로 $로 바뀐다. delete$hi_temps{"Tue"}; (삭제도 가능)

Pointer and Reference Types
C에서 쓸 수 있는 것은 Pointer. C++에서 쓸 수 있는 것은 Pointer & Reference, Java랑 Python에서는 Reference
레퍼런스는 const 포인터다. 내용을 바꿀 수 없다. 포인트는 주소를 바꿀 수 있다.
int &b; b=c; 하면 b의 값 c를 못 바꾼다.
즉, Pointer type 변수는 값에 대한 주소를 가르키는 것. 값이 저장되어 있는 주소 값이다.
주소 값이 의미가 없어졌으면 Null 값으로 바뀌어야 한다.
(장점 : indirect addressing 가능, Dynamic하게 메모리를 관리 가능) (Heap 영역에 동적으로 할당되는 주소를 가르키는 것이 장점) (Global 변수에 포인터를 만들면 Data 영역도 가르킴) (Local 변수에 포인터를 만들면 Stack영역을 가르킴)


Type Checking
프로그래밍 언어에서, 내 언어 안에서 사용하고 있는 데이터 타입들이 적절하게 쓰이고 있는지 검사하는 것.
여러 문장들이 문법에 맞게 사용되고 있는지 보는 것이 Syntax 분석.
그 다음에 컴파일러나 인터프리터가 Type checking을 한다.
- Compatible type : 언어가 정해놓은 규칙에 의해서 서로 호환이 되는 타입 (coercion=강제변환 이라고 한다) => 연산자에 대해 합법적이거나, 컴파일러 생성 코드에 의해 암시적으로 변환될 수 있는 언어 규칙에 따라 허용된 타입
- Type error : 부적절한 유형의 피연산자에 연산자를 적용하는 것
만약 모든 타입 바인딩이 정적인 경우, 거의 모든 타입 체크는 정적으로 이루어질 수 있다. (runtime 전에 타입 체킹)
만약 타입 바인딩이 동적이라면, 타입 체크는 동적으로 이루어져야 한다. (runtime 중에 타입 체킹)
타입 바인딩이 동적이면 타입 체크는 무조건 동적 / 타입 바인딩이 정적이면 타입 체크 중 일부는 동적일 수 있음
프로그래밍 언어가 강한 타입 시스템(strongly typed)을 가지면 타입 에러가 항상 검출된다는 장점이 있다.
강한 타입 시스템의 장점은 변수의 잘못된 사용으로 인한 타입 에러를 감지할 수 있다는 것이다.
프로그래밍 언어의 Type checking


'Programming Languages [PL]' 카테고리의 다른 글
| [PL] 07. Statement-Level Control Structures (3) | 2024.01.10 |
|---|---|
| [PL] 06. Expressions and Assignment Statements (3) | 2024.01.10 |
| [PL] 04. Names, Bindings, and Scopes (7) | 2024.01.09 |
| [PL] 03. Lexical and Syntax Analysis (1) | 2024.01.09 |
| [PL] 02. Describing Syntax and Semantics (1) | 2024.01.09 |



